
Dankzij AI kun je analyses loslaten op je artikelen, die eerder niet mogelijk waren
Deze nieuwsbrief schrijf ik vanuit een koffietentje in Austin, Texas. Gisteren is daar de SXSW 2024 begonnen, de jaarlijkse combinatie van een conferentie en festival die bestaat uit de onderdelen Interactive, Film en Music. Ik ben er voor de zevende keer voor het Interactive deel en uiteraard specifiek om te kijken welke ontwikkelingen er gaande zijn op het gebied van online media. SXSW helpt me altijd weer om verbanden te leggen en grote lijnen te zien en tegelijkertijd om een paar specifieke, nieuwe inzichten op te doen.
We zijn pas één dag op weg, dus ik ga er nog niet inhoudelijk op in, maar uiteraard ga ik dat de komende edities wel doen. De eerste keer is komende woensdag, dan praat ik premium-deluxe-plus-leden bij.
In deze nieuwsbrief wil ik het met je hebben over:
- Dankzij taalmodellen kun je nieuwe inzichten krijgen over de artikelen die je publiceert.
- De Digital Markets Act is ingegaan, maar de vraag is of hij het gewenste effect heeft.
Dankzij taalmodellen kun je nieuwe inzichten krijgen over de artikelen die je publiceert
Veel redacties hebben de laatste jaren geïnvesteerd om meer inzicht te krijgen in het gedrag van het publiek. Welke verhalen doen het goed? Hoe lang blijven bezoekers gemiddeld op de site? Waar komen lezers vandaan?
Er zijn echter veel vragen die niet beantwoord kunnen worden, in het bijzonder als het gaat om soorten verhalen. Wat is de ontwikkeling van het leesgedrag van verhalen over de oorlog in Oekraïne? Wat voor soort verhalen doet het goed op welk moment van de dag?
Het probleem hierbij is over het algemeen dat er geen data beschikbaar is over de inhoud van het verhaal. Ja, de categorie waar het in geplaatst is, is bekend. Met een beetje geluk zijn ook door de redactie toegevoegde tags of de lengte van een verhaal beschikbaar in een analyse-tool, maar dan houdt het vaak wel op.
Uiteraard kun je meer metadata bij artikelen toevoegen en doorsturen naar je analytics-systeem (of twee datasets koppelen). Het toevoegen van extra metadata zorgt echter voor flink wat extra werk voor de redactie én je moet vooraf nadenken wat je in de toekomst eventueel nodig gaat hebben. Daarnaast heb je ook nog het risico dat redacteurs er verschillend mee omgaan.
Generatieve AI kan mogelijk een oplossing bieden. Als je artikelen voert aan een systeem als GPT 4.0 kan het allerlei vragen over die teksten beantwoorden en kun je hem dus ook vragen om bepaalde metadata te genereren. Uiteraard moet je testen of dit bruikbare resultaten oplevert, maar als dat zo is en je hebt het ingericht, dan heb je er geen werk meer aan. De extra metadata kun je vervolgens koppelen aan je artikelen om analyses te kunnen.
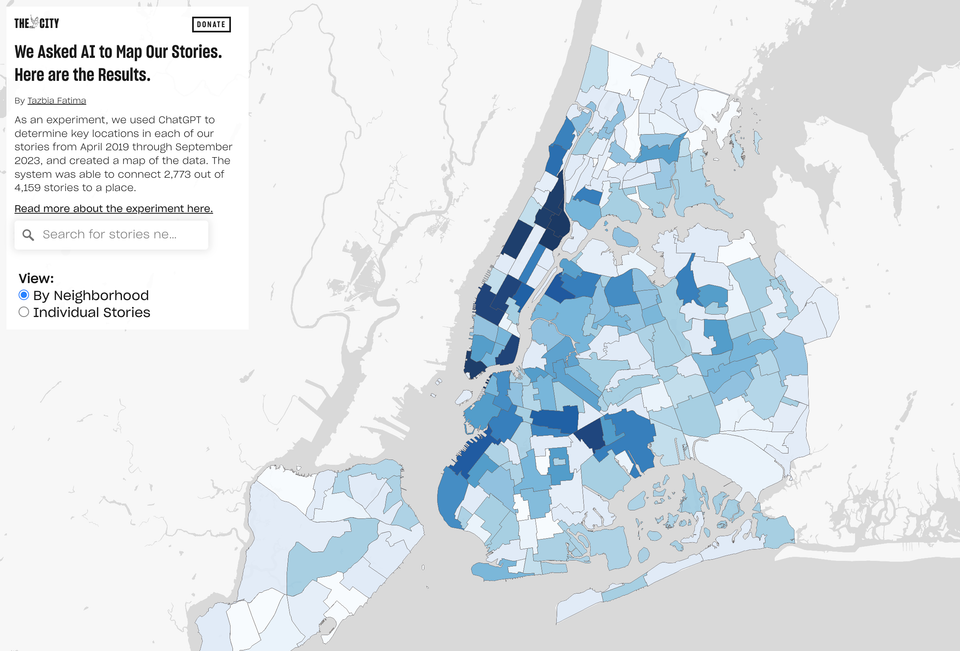
Een mooi voorbeeld komt van THE CITY in New York. De redactie heeft als doel om inwoners van alle vijf de stadsdelen te bedienen, en dus verhalen te maken over wat daar gebeurt, maar het is niet makkelijk een antwoord krijgen op de vraag of het dat ook deed. Het besloot daarom om vijf jaar aan artikelen te voeren aan ChatGPT en te vragen waar het zich afspeelt. Bij twee derde van de verhalen lukte dat en het bleek ook nog eens te kloppen. De meeste van de stukken konden zelfs gekoppeld worden aan een specifieke buurt. Vervolgens zijn alle artikelen op een kaart geplot. In een artikel gaat THE CITY in op hoe ze dit hebben gedaan.
Het project doet me denken aan de nieuwskaart die regionale omroepen vijf jaar geleden ontwikkelden. Alleen moest daar de plaats waar nieuws zich afspeelt handmatig worden toegevoegd aan ieder artikel. Dat zou nu dus geautomatiseerd kunnen worden.
Afgelopen zomer schreef ik over Overtone.AI. Dit is een startup die met behulp van kunstmatige intelligentie artikelen analyseert om vast te stellen wat voor soort stuk het is: een snel nieuwtje, een interview, een achtergrondverhaal of een opiniestuk. Dat is natuurlijk iets heel anders dan de locatie van een nieuwsgebeurtenis, maar ook een voorbeeld van data over artikelen die nieuwe inzichten kan opleveren.
Ik gok dat op iedere redactie wel vragen leven over hoe een bepaald soort artikelen het doet. Of over welk aandeel van de totale productie over een specifiek onderwerp gaat. Dankzij kunstmatige intelligentie is het mogelijk een antwoord te krijgen op die vragen zonder handmatig alle artikelen te hoeven indelen. Daar zul je nu nog wel even voor moeten knutselen met een taalmodel als GPT 4.0, maar ik verwacht dat er uiteindelijk analysetools komen die dit inbouwen.
Word beter in het maken van video's met je smartphone [adv]

Werk je als journalist of videomaker en wil je beter worden in het maken van video's met je smartphone? Volg dan een training van Geertje Algera!
Geertje werkte in het verleden als mobiel journalist bij KRO-NCRV en schreef het boek 'Professionele video’s maken met je smartphone'. Op vrijdag 12 april geeft ze de cursus 'Smartphone video’s maken Level Up', speciaal bedoeld voor mediamakers die al ervaring hebben, maar nog beter willen worden. Tijdens deze inspirerende (en praktische) dag leer je onder meer over: shots maken met impact, monteren in Lumafusion en InShot, stop motion video, korte verticale video’s zoals TikToks & Reels, gear en natuurlijk de nieuwste ontwikkelingen rond AI video editing. Ook ontvang je het boek 'Professionele video’s maken met je smartphone' als naslagwerk.
Alle details en de mogelijkheid om je aan te melden, vind je op Geertje’s website.


De Digital Markets Act is ingegaan, maar de vraag is of hij het gewenste effect heeft
Het kan niet anders dan dat je er iets van hebt gekregen. En software-update op je telefoon, een mailtje met wijzigingen met gebruikersvoorwaarden, een popup waarin je toestemming moet geven voor het gebruik/uitwisseling van je gegevens. Afgelopen week ging de Digital Markets Act (DMA) in.
Ik heb hier het afgelopen jaar al wel een over geschreven of aan gerefereerd, omdat het de wetgeving zorgt dat de techreuzen zich moeten houden aan nieuwe regels die hun machtspositie zouden moeten verkleinen. Iets dat in principe goed nieuws zou moeten zijn voor andere bedrijven en consumenten.
De wetgeving draait om het reguleren van de core platform services van de zes grootste bedrijven op internet: Alphabet, Amazon, Apple, ByteDance, Meta en Microsoft. Per bedrijf verschilt het of een dienst hieronder valt, afhankelijk van het marktaandeel. Zo valt Apple's iMessage niet onder de regels, maar WhatsApp wel.
Er zijn op dit moment verschillende soorten diensten gereguleerd:
- Sociale netwerken: TikTok, Facebook, Instagram en LinkedIn
- Bemiddelingsdiensten: Google Maps, Google Play, Google Shopping, Amazon Marketplace, iOS App Store enMeta Marketplace
- Advertentiesystemen: Google, Amazon en Meta
- Browsers: Chrome en Safari
- Besturingssystemen: Android, iOS en Windows
- Nummer-onafhankelijke interpersoonlijke communicatiediensten (oftewel: chatapps): WhatsApp en Facebook Messenger
- Zoekmachines: Google
- Platformen om video's te delen: YouTube
- Clouddiensten: hier vallen nog geen diensten onder op dit moment
- Virtuele assistenten: hier vallen nog geen diensten onder op dit moment
TechCrunch schreef een lang artikel met meer uitleg over de wet en hoe de bedrijven/diensten hier aan voldoen. In mijn ogen zeer de moeite waard om eens door te lezen.
 Natasha Lomas
Natasha Lomas
Wat opvalt bij het voldoen aan de DMA is dat de techbedrijven, niet geheel verrassend, zoeken naar de mazen in de wet. Hoe kunnen ze aan de wet voldoen zonder dat ze er te veel last van hebben. Vooral Apple lijkt daar bijzonder goed in geslaagd door het aanbieden van apps en betalingen buiten de App Store om complex en duur te maken. De vraag is nog of Apple uiteindelijk juridisch wel echt voldoet aan de DMA, maar het bedrijf handelt in ieder geval niet echt naar de geest van de wet.
Nu de DMA is ingevoerd, neemt ook de kritiek toe. En dan niet zozeer vanuit de bedrijven die gereguleerd worden, maar kritiek of de DMA zijn doel wel bereikt. De wet moet de machtspositie van 'de grote zes' verkleinen en ruimte creëren voor andere bedrijven, maar je kunt je afvragen of dat in de praktijk gebeurt. Mede doordat de techbedrijven helemaal zelfstandig hebben kunnen bepalen hoe ze aan de regels voldoen, schrijft The Verge.
Many of these companies have announced compliance plans in response to the DMA, and for the most part, these changes — as one might expect from a plan crafted by the company itself — are unlikely to result in a loss of power. And then there’s Apple, which appears to be engaging in outright malicious compliance, leaving European developers at a disadvantage.
Het is uiteraard nog te vroeg om harde conclusies te trekken, maar wie had verwacht dat Alphabet, Amazon, Apple, ByteDance, Meta en Microsoft echt heel veel minder macht zouden krijgen op de Europese markt komt waarschijnlijk bedrogen uit.
Kort
- RTL Nieuws heeft het 'plan van aanpak publieke omroep' in handen, dat een reactie is op het rapport van de commissie-Van Rijn over grensoverschrijdend gedrag bij de publieke omroep. Er is veel aandacht voor presentatoren, die continu begeleiding moeten krijgen. En omroepdirecteuren mogen nog maar maximaal tien jaar hun functie bekleden. De vraag is natuurlijk of ze daarna bij een andere omroep (of de NPO) nog een keer tien jaar de baas mogen zijn...
- Journalisten die online gesponsorde posts plaatsen op social media, moet dat kunnen? Het Stimulerings voor de Journalistiek schreef er een stuk over.
- Volgens het Europese Hof voor Justitie is een veelgebruikte cookiemuur, die van de IAB, in strijd met de Europese privacywetgeving GDPR. Er worden namelijk voorkeuren van gebruikers uitgewisseld tussen websites die de tool gebruiken en dat mag niet.
- Na Apple gaat ook Google in de EU geld vragen van ontwikkelaars die in-app-aankopen buiten de Google Play Store om laten lopen, bijvoorbeeld voor abonnementen. En net als Apple zegt Google dat te doen omdat het runnen van de Play Store veel meer inhoudt (en kost) dan het verwerken van betaling.
- In tegenstelling tot andere social media, wil LinkedIn meer inzetten op nieuws. Het helpt daarom nieuwsorganisaties en journalisten actief met ondersteuning.
- X heeft een nieuwe functie voor betalende gebruikers: Articles. Hiermee kun je volledige artikelen op het platform publiceren.
- TikTok zet vol in op langere video's. Het gaat makers die zijn aangesloten bij het Creator Rewards Program betalen voor het maken van video's die langer dan een minuut duren.