
De Volkskrant deelt artikelen van De Speld alsof het echt nieuws is
Na drie rommelige weken pak ik het vaste ritme van mijn nieuwsbrief weer op: elke zaterdagochtend verstuur ik een gratis editie en elke woensdag een editie voor betalende leden.
In deze editie wil ik het met je hebben over:
- De Volkskrant verspreidt artikelen van De Speld alsof het nieuws is.
- Na social media willen techbedrijven ons nu verslaafd maken aan AI.
De Volkskrant verspreidt artikelen van De Speld alsof het nieuws is
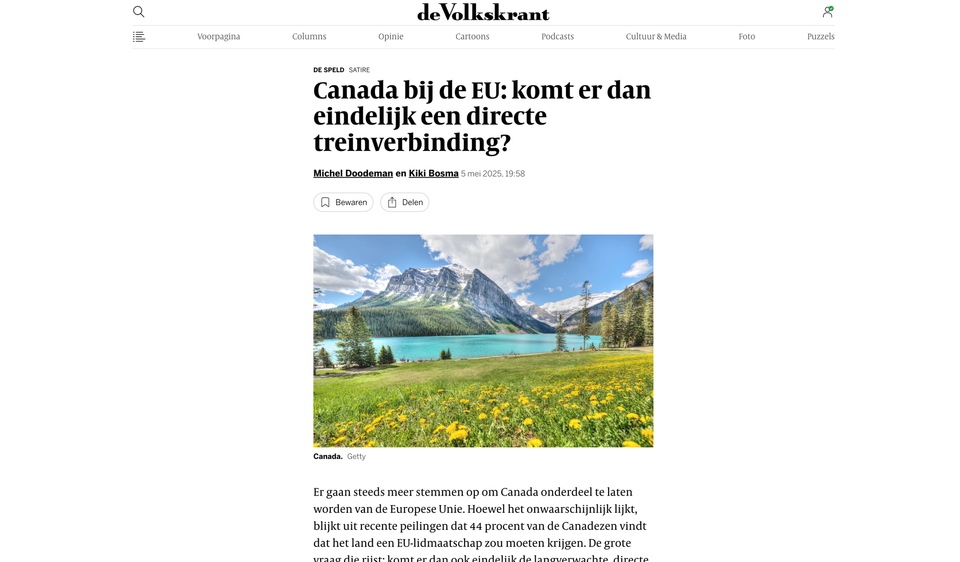
Afgelopen week zag ik een opvallende kop in Google Discover, dat is het lijstje (nieuws)artikelen dat Google op basis van je interesses/leesgedrag toont. De kop van het artikel luidde: 'Canada bij de EU: komt er dan eindelijk een directe treinverbinding?'
Uit interesse klikte ik door en begon ik met het lezen van het stuk:
Er gaan steeds meer stemmen op om Canada onderdeel te laten worden van de Europese Unie. Hoewel het onwaarschijnlijk lijkt, blijkt uit recente peilingen dat 44 procent van de Canadezen vindt dat het land een EU-lidmaatschap zou moeten krijgen. De grote vraag die rijst: komt er dan ook eindelijk de langverwachte, directe treinverbinding tussen Canada en Europa? Als het aan premier Mark Carney ligt wel. Hij presenteert zijn plan voor een nieuwe hogesnelheidstrein.
‘Mensen vragen zich al jaren af: waarom zijn Europa en Canada zo slecht met elkaar verbonden per trein? We hebben het vrijehandelsverdrag CETA al, dus we zijn al praktisch deel van de EU. Met de Intercontinentalcity zijn Canadese reizigers in één vijftig uur durende handomdraai in Europa’, zegt Carney.
Ik vond het al direct een vreemd nieuwsbericht, maar bij de tweede alinea wist ik het zeker: dit is satire. En nu weet ik dat De Volkskrant een samenwerking heeft met De Speld waarbij het artikelen van de satirische website op de achterkant plaatst, maar dit was een gewoon nieuwsartikel. Onder het artikel stond ook geen opmerking over de herkomst van het stuk. Totdat mijn oog plots op een paar kleine lettertjes viel...
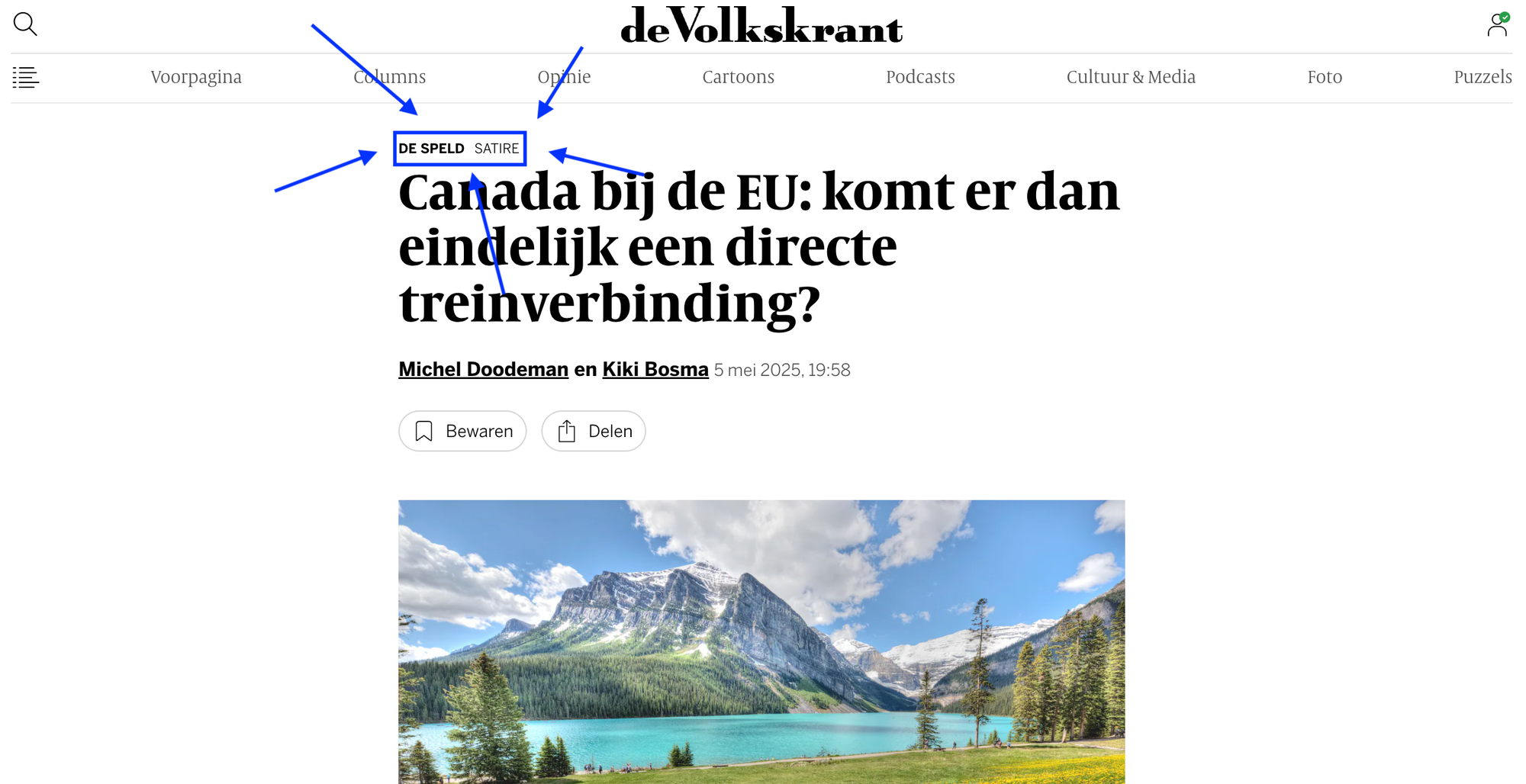
Superleuk dat De Speld een rubriekje heeft op de achterpagina van de krant, maar daar staan de stukken in een specifieke context en lay-out. Op Volkskrant.nl worden de stukken uit de context én de lay-out gehaald en dat zijn nou precies de twee dingen die verwarring kunnen voorkomen. En vervolgens komen ze ook nog iets op platforms zoals Google News/Discover terecht waar het als nieuwskop wordt gepresenteerd.
Een satirisch artikel dat wordt verspreid door een journalistieke organisatie moet te allen tijde direct herkenbaar zijn als dusdanig qua lay-out en ook een duidelijke disclaimer in tekst moeten hebben. Daarnaast mag de link naar zo'n stuk op social media of in een zoekmachine ook nooit het idee geven dat het een echt nieuwsartikel is. Dat gebeurt hier wel, mede doordat het als Volkskrant-artikel wordt aangemerkt.
Een klein beetje uitzoekwerk leerde me dat de redactie van De Volkskrant normaal gesproken nog even handmatig 'De Speld:' aan het begin van de kop zet om dit af te vangen, maar dat wordt dus blijkbaar ook wel eens vergeten én je kunt je afvragen of iedereen die de artikelen online tegenkomt weet wat De Speld is. Dat Google Nieuws vol staat met dit soort artikelen, vind ik zeer twijfelachtig:
En dan ga je er nu nog vanuit dat het mensen zijn die het lezen. Als mensen vragen over het nieuws gaan stellen aan AI-chatbots is de kans groot dat die zich baseren op actuele kennis die de systemen ophalen van nieuwssites. Nu blokkeert De Volkskrant die bots nog actief, maar stel je voor dat DPG Media een deal sluit met OpenAI, dan is de kans groot dat ChatGPT uit De Speld-artikelen gaat putten alsof het nieuwsartikelen zijn.
Nu hebben chatbots het wel vaker moeilijk met feiten, maar dat zou De Volkskrant er niet van moeten weerhouden om te voorkomen dat satirische artikelen leiden tot desinformatie.
De beste oplossing zou zijn dat De Volkskrant de stukken van De Speld simpelweg niet als losse artikelen verspreidt. Ze hebben een plek in de krant en De Speld kan ze op zijn eigen site plaatsen, op Volkskrant.nl en op externe platforms hebben de stukken buiten de context en lay-out van de volledige krant niets te zoeken.
Na social media willen techbedrijven ons nu verslaafd maken aan AI
OpenAI heeft begin vorige week de uitrol van een nieuwe versie van het meestgebruikte taalmodel in ChatGPT teruggedraaid. De reden? Het taalmodel was overdreven vriendelijk en complimenteus en gaf bevestiging op de meest rare vragen, in de hoop gebruikers daarmee tevreden te stellen.
Wat bleek is dat het AI-bedrijf de feedback van gebruikers op de reactie van de chatbot via de duimpjes die onder elke reactie staan was gaan meewegen in het model. Gebruikers geven blijkbaar een duimpje omhoog als het model heel erg vriendelijk is, dus het model ging veel vleiendere reacties geven. Kortgezegd: de chatbot ging slijmen. En daar was in ieder geval een groot deel van de gebruikers zo ontstemd over, dat de makers de versie van het taalmodel hebben teruggetrokken.
In de podcast Hard Fork van The New York Times, uiten techjournalisten Casey Newton en Kevin Roose naar aanleiding hiervan hun zorgen over de optimalisatiedrang van AI-bedrijven. Dit foutje van OpenAI is daar slechts een voorbeeld van. Meta liet chatbots die zijn vormgegeven als een specifiek karakter seksueel getinte gesprekken voeren. Het was zelfs mogelijk voor minderjarige gebruikers om een soort seksuele rollenspellen te spelen waarin je praatte met stemmen van beroemdheden, onthulde The Wall Street Journal.
Meta koos er bewust voor om de beperkingen van deze systemen te versoepelen, waardoor dit kon gebeuren, omdat dat goed was voor de engagement: gebruikers gingen dan meer chatten. De verbeterslag die OpenAI wilde maken met ChatGPT had uiteindelijk hetzelfde doel: het model zo aanpassen dat gebruikers het nog meer gaan gebruiken.
Dit is uiteindelijk de modus operandi die we kennen van de techreuzen; Meta voorop. Ze optimaliseren hun platforms op zo'n manier dat mensen er zoveel mogelijk tijd op spenderen. Bij social media beginnen we inmiddels in te zien wat de keerzijde daarvan is. Bij kunstmatige intelligentie, wat een technologie is met serieuze risico's, gebeurt nu precies hetzelfde nog een keer.
Mark Zuckerberg ziet een wereld voor zich waarin iedereen meerdere virtuele vrienden heeft. Hij denkt dat het een oplossing is tegen eenzaamheid. En de toekomst van social-media-apps bestaat binnen de visie van Meta voor een groot deel uit media die door AI is gegenereerd.
In de VS heeft het bedrijf een app uitgebracht voor Meta AI, waarmee je kunt chatten en afbeeldingen genereren. Tegelijkertijd heeft de app een feed die een deel van wat je vraagt aan de AI deelt met je vrienden. De feed zelf laat dus alleen maar AI-gegenereerde crap zien en tegelijkertijd wordt een deel van wat je doet in de app automatisch openbaar.
Vorige week schreef ik al dat OpenAI ook bezig is met een sociaal netwerk rondom AI-creaties. Alles om er maar voor te zorgen dat we zoveel mogelijk gaan doen binnen de platforms die deze bedrijven ontwikkelen.
En nu zijn we er uiteraard zelf bij met zijn allen, maar als social media ons iets hebben geleerd, is het wel dat de verslavende werking van het netwerkeffect en de dark patterns die deze bedrijven gebruiken ervoor zorgen dat we dingen gaan doen waar we misschien wel helemaal niet echt gelukkig van worden.
Als we het hebben over de gevolgen van de opkomst van AI dan gaat het vaak over grote economische en maatschappelijke veranderingen. Als er één ding is dat daar in mijn ogen niet bij hoort, dan is dat wel dat we met zijn allen verslaafd worden gemaakt aan dingen die in de kern compleet nutteloos zijn, maar ons ook nog eens diep ongelukkig kunnen maken.
Kort
- Nederland is een plek gestegen op de persvrijheidsindex van Reporters Sans Frontières. Nederland staat nu op plek 3, ondanks een toename van het aantal bedreigingen tegen journalisten.
- Wereldwijd stond het er nog nooit zo slecht voor met de persvrijheid sinds Reporters Sans Frontières de index maakt. Niet geheel verrassend bereikte de persvrijheid in de VS een dieptepunt.
- DPG Media krijgt een soort van laatste kans om de ACM te overtuigen van het belang van de overname van RTL Nederland. Hiervoor wordt er een hoorzitting opgetuigd. De toezichthouder heeft na anderhalf jaar nog steeds geen toestemming gegeven voor de deal.
- NOS-directeur Renate Eringa ziet de komende maanden af van haar salaris, om op die manier te compenseren voor de exorbitant hoge vergoeding die ze vorig jaar als interim-directeur verdiende, terwijl ze al had afgesproken langer te blijven.
- De stichting Huis voor de Journalistiek wil gaan onderzoeken hoe een huis voor de journalistiek eruit gaat zien en organiseert in september de eerste editie van het Nederlands Journalistiek Festival. Om deze plannen daadwerkelijk te kunnen uitvoeren is de stichting een crowdfundingcampagne begonnen.
- Laurens Vreekamp schreef voor Villamedia een interessant stuk over wat er gebeurt als het publiek de journalistiek niet meer bij de bron haalt, maar enkel nog via AI-systemen van techbedrijven.
- Een meerderheid van de Amerikanen denkt negatief over het effect dat kunstmatige intelligentie in de toekomst gaat hebben op het nieuws, blijkt uit onderzoek van het Pew Research Center. Men verwacht dat er in de toekomst minder journalisten zullen zijn.
- De kracht van de platformfuncties van Substack is niet alleen aantrekkelijk voor zelfstandige makers, maar zelfs voor uitgevers. New York Magazine is gestart met een nieuwsbrief op Substack.
- De Amerikaanse uitgever Vox Media heeft de populaire gamingsite Polygon verkocht aan de Canadese uitgever Valnet, een groot deel van de redactie is ontslagen.
- OpenAI blijft toch een non-profit-organisatie. Het bedrijf wilde zichzelf omvormen tot commercieel bedrijf, maar ziet daar uiteindelijk vanaf.
- Pinterest staat vol met door kunstmatige intelligentie gegenereerde troep, waardoor het platform voor veel gebruikers onbruikbaar wordt. Pinterest gaat er eindelijk wat aan doen en geeft gebruikers de mogelijkheid AI-afbeeldingen te verbergen. De vraag is hoe dat in de praktijk gaat werken.
- Spotify gaat bij podcasts tonen hoe vaak ze zijn afgespeeld, net als YouTube al sinds jaar en dag doet met video's.
- Een belangrijke gerechtelijke uitspraak in de VS: Apple mag app-makers niet langer dwingen om aankopen en abonnementen in apps enkel via de App Store te laten lopen. Apple verdient daar 30 procent aan. De Europese Commissie heeft middels de Digital Markets Act ook al opgetreden tegen deze vorm van machtsmisbruik door Apple. Het techbedrijf staat het in de VS nu toe om vanuit een app te linken naar andere manieren om te betalen.