
Chatbots gaan onzorgvuldig om met het nieuws waar media hen toegang toe geven, met alle gevolgen vandien

Op het moment dat deze nieuwsbrief je inbox binnenkomt, begint mijn vakantie. De komende vier weken ga ik er met mijn gezin naar Florida. Dat betekent dat ik mijn eerstvolgende nieuwsbrief verstuur op woensdag 26 november, speciaal voor betalende leden. De zaterdag daarop verstuur ik weer een reguliere nieuwsbrief.
Mocht je willen weten wanneer je me moet missen in je mailbox: op mijn site staat een publicatieschema staan, waar ik in principe ruim vooraf aankondig waarin ik ruim van tevoren aankondig wanneer ik geen nieuwsbrief verstuur.
In deze laatste editie voor mijn vakantie wil ik het hebben over een interessant onderzoek naar hoe chatbots omgaan met nieuws.
Bijna de helft van alle antwoorden die chatbots op vragen over nieuws geven bevat significante fouten
In februari publiceerde de BBC een onderzoek dat het had gedaan naar fouten die chatbots maken bij het samenvatten van nieuwsartikelen. Met meer dan de helft van de samenvattingen was iets significants mis.
Bij 19 procent van de artikelen stonden er feitelijke onjuistheden, bijvoorbeeld verkeerde getallen of data. In 13 procent klopte er iets niet in quotes die door de chatbot werden aangehaald; deze waren aangepast of stonden zelfs helemaal niet in het originele artikel van de BBC, hoewel die wel als bron werd opgevoerd. Van de vier onderzochte chatbots waren de antwoorden van Gemini diegenen waar het vaakst iets mis mee was.
Het onderzoek van de BBC was aanleiding om dit grootschaliger aan te pakken. De onderzoekers van de BBC zijn opgetrokken met de EBU, de overkoepelende organisatie van Europese publieke omroepen. 22 omroepen hebben meegewerkt aan het vervolgonderzoek, waardoor er in 18 landen onderzoek gedaan is naar de fouten die chatbots maken als je ze vragen stelt over het nieuws. Ook Nederland is hierin vertegenwoordigd, via de NOS en NPO.
Voor het onderzoek is een lijst met 30 belangrijke nieuwsvragen vastgesteld op basis van vragen die het publiek daadwerkelijk stelt. Daarnaast heeft elke omroep de mogelijkheid gehad om voor hun eigen land vragen toe te voegen over nieuwsonderwerpen die daar spelen. Deze vragen zijn vervolgens in mei en juni van dit jaar in de lokale taal gesteld aan de gratis versies van ChatGPT, Copilot, Perplexity en Gemini. Vervolgens zijn de reacties beoordeeld door journalisten van deelnemende omroepen op het gebied van feitelijke correctheid, bronvermelding, onderscheid tussen feit en mening, kleur (een taalmodel voegt woorden toe die een bepaalde mening of waardeoordeel impliceren) en context.
Het resultaat: met 45 procent van alle antwoorden van de chatbots op nieuwsvragen waren significante problemen. En daarbij gingen de meest voorkomende problemen om bronvermelding en feitelijke correctheid.
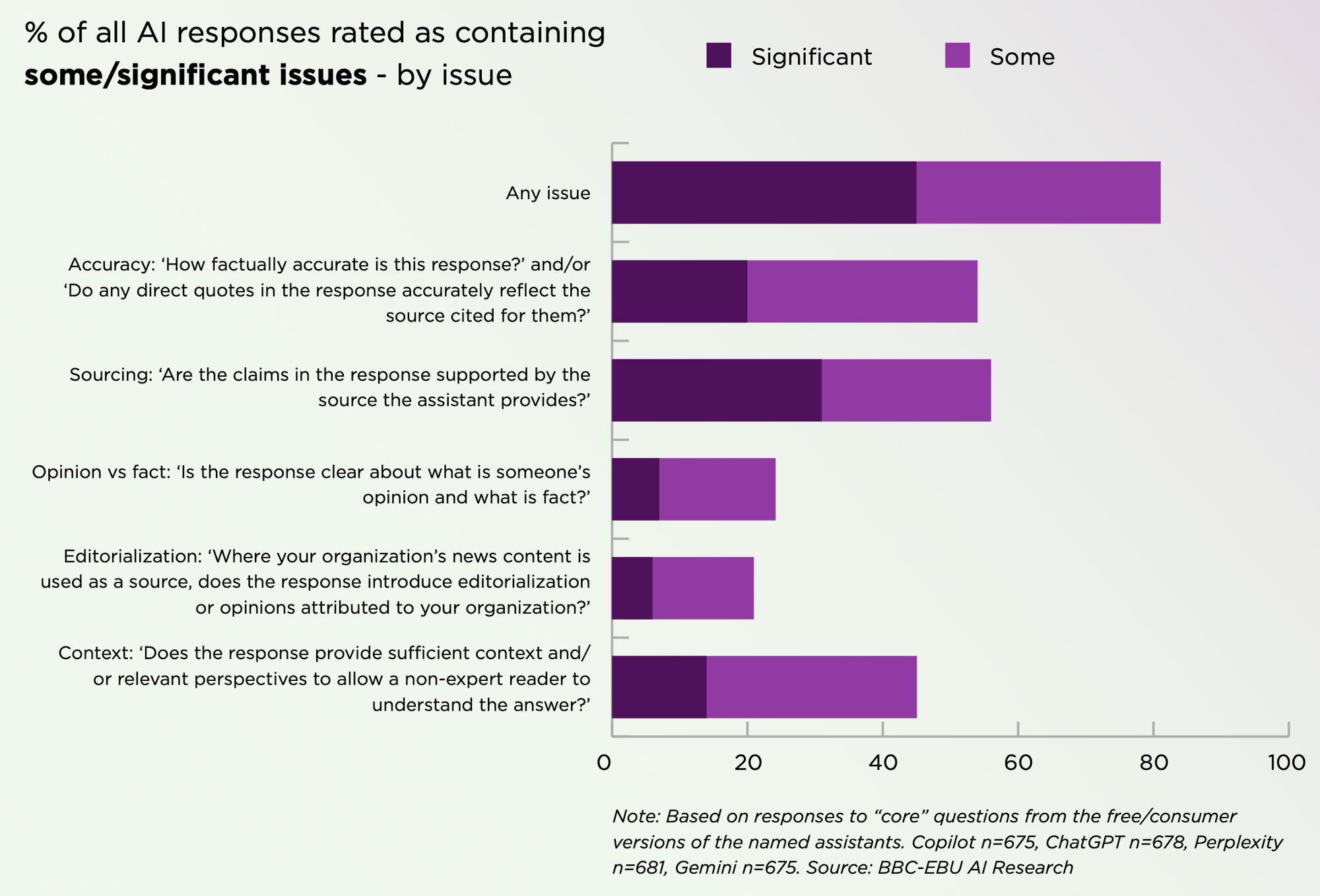
Bij het onderzoek van de BBC uit februari was er het vaakst iets mis met de reacties van Google's chatbot Gemini. Dat is ook in dit onderzoek het geval. Waar het aantal significante problemen op het gebied van feitelijke correctheid bij alle chatbots rond de 15-20 procent, zijn de verschillen bij bronvermelding groot. Bij Gemini zijn er bij meer dan twee derde van alle antwoorden significantie problemen met de bronvermelding. Dat resulteert erin dat de antwoorden van Gemini zo'n twee keer zo vaak significante problemen zijn als bij de concurrentie.
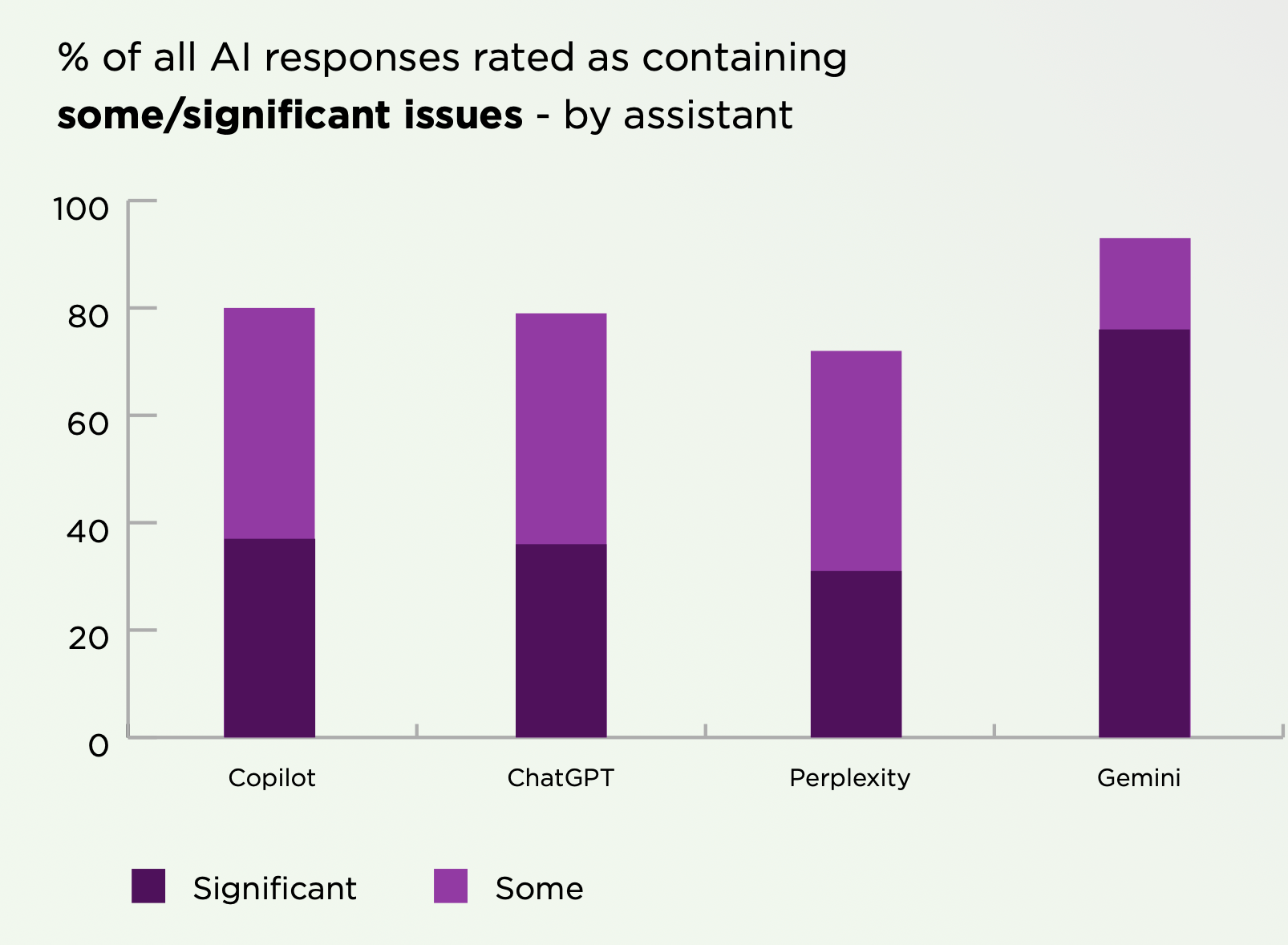
Over de problemen met de bronvermelding bij Gemini schrijven de onderzoekers:
42% of Gemini responses provided no direct sources (URLs pointing to specific pieces of content), meaning users cannot verify the claims in the response. Gemini also showed a strong tendency to make incorrect or unverifiable sourcing claims. This most commonly occurred through the use of phrases such as “According to available information, particularly from Radio France …”, “sources such as RTBF say …”, “according to RTVE and other sources …”, accompanied by either a citation to a URL for a different media organization or source, or no direct source at all. Evaluators noted this type of sourcing behaviour in 54% of Gemini responses. This specific issue disproportionately affected Gemini – no other assistant had more than 4% responses impacted.
Een relatief klein probleem betreft het toevoegen van 'kleur' aan antwoorden. Chatbots zijn soms niet neutraal in hun antwoorden en voegen in hun woordkeuze kleur toe aan het feit, waarbij ze dat impliciet toewijzen aan een nieuwsbron. Het is iets wat de gemiddelde gebruiker niet zo gauw zou merken en mensen komen daardoor ook niet in aanraking met onjuiste informatie, maar het kan er bijvoorbeeld wel voor zorgen dat gebruikers een bepaald nieuwsmerk een politieke kleur meegeven die het niet heeft. In het onderzoek wordt hiervan een Nederlands voorbeeld aangehaald:
ChatGPT (NOS/NPO), in a response about climate change, talked about “positive developments” and “positive steps in the fight against climate change”. As NOS/NPO said, “In this case, ‘positive’ is a values-based word: measures that are seen as progressive by one individual may be viewed as inadequate or harmful by others. As there are no sources attributed to these claims, but the rest of the sources in the response were NOS, the reader may attribute these claims to NOS. As a result, they may question the impartiality of NOS.”
Sowieso staat het hele rapport (pdf) vol met voorbeelden om wat meer gevoel te krijgen bij het soort problemen dat er zijn als het gaat om chatbots en nieuws.
Volgens mij moet je het hele onderzoek niet alleen zien in de context van de risico’s van het gebruik van chatbots voor nieuws. En voor de duidelijkheid: die zijn er zeker, want ze worden inmiddels door ongeveer net zoveel mensen gebruikt als nieuwsbron als TikTok, X en LinkedIn.
Het probleem is echter vooral dat nieuwsmedia er bewust voor kiezen om toe te laten dat chatbots hun nieuws gebruiken en daar vervolgens niet zorgvuldig mee omgaan of zelfs dingen doen die schadelijk kunnen zijn voor het vertrouwen in de nieuwsmerken. Dat doen nieuwsmedia omdat ze hopen dat het verkeer oplevert of omdat ze een deal sluiten met een techbedrijf als extra inkomstenbron. Als je naar deze onderzoeksresultaten kijkt is het eigenlijk onbegrijpelijk dat nieuwsmedia dat doen.
Er is uiteraard ook een andere kant: als chatbots geen toegang hebben tot betrouwbare informatie kan de kwaliteit van de antwoorden verder omlaag gaan, terwijl steeds meer mensen chatbots gebruiken om aan nieuws en informatie te komen. Uit een soort maatschappelijk/democratisch oogpunt zou je dus kunnen zeggen dat nieuwsmedia en zeker publieke omroepen chatbots juist zouden moeten voeden met hun nieuws. Het zorgt voor een spagaat, waarbij we waarschijnlijk over een aantal jaren terugkijken en concluderen dat de verkeerde keuze is gemaakt. Om de simpele reden dat er eigenlijk geen goede keuze is.
Kort
- De NPO wil zijn televisiezenders anders gaan indelen. Op NPO 2 zullen overdag kinder- en jeugdprogramma's worden uitgezonden; NPO 3 moet een zender worden voor evenementen en een soort etalagekanaal voor NPO Start. Als je het mij vraagt, maakt dat de weg vrij om de zender over een paar jaar op te doeken.
- Instagram en Facebook zijn drie weken geleden door de voorzieningenrechter in Amsterdam verplicht om gebruikers de mogelijkheid te geven om standaard een chronologische tijdlijn te zien in plaats van de algoritmische. Meta heeft deze verplichte wijziging echter niet doorgevoerd, terwijl de deadline die de rechter had opgelegd dinsdag is verstreken. Dat betekent dat het techbedrijf een dwangsom van 100.000 euro per dag moet betalen aan burgerrechtenorganisatie Bits of Freedom.
- Instagram heeft de mogelijkheid om afbeeldingen te bewerken met generatieve AI onderdeel gemaakt van de app, waardoor dit soort tools nog toegankelijker worden. Binnen de EU heeft Meta deze technologie echter (nog) niet beschikbaar gemaakt.
- In het verlengde daarvan: met de app Endless Summer kun je "vakantiefoto's" genereren met behulp van AI, want stel je voor dat je echt op vakantie zou moeten...
- Wat er precies werkt op Google Discover en wat niet, is een beetje een mysterie. Toch is het iets wat heel veel uitgevers heel graag willen weten. SEO-specialisten doen dan ook veel moeite om grip te krijgen op het algoritme achter de artikelenfeed van Google. En sommigen lijken inmiddels wat praktische tips te hebben verzameld voor wat er goed werkt om meer verkeer uit Google Discover te halen.
- Reddit spant een rechtszaak aan tegen Perplexity, omdat dat AI-bedrijf zonder toestemming Reddit zou hebben leeggetrokken om te dienen als trainingsdata voor de taalmodellen van het bedrijf.